Positional Encoding and Input Embedding in Transformers - Part 3

Transformers From Scratch - Part 1 | Positional Encoding, Attention, Layer NormalizationПодробнее
Stanford XCS224U: NLU I Contextual Word Representations, Part 3: Positional Encoding I Spring 2023Подробнее

Chatgpt Transformer Positional Embeddings in 60 secondsПодробнее

"Attention Is All You Need" Paper Deep Dive; Transformers, Seq2Se2 Models, and Attention Mechanism.Подробнее

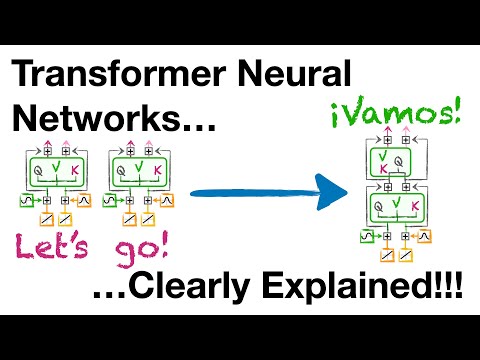
Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!!Подробнее
Attention is all you need (Transformer) - Model explanation (including math), Inference and TrainingПодробнее
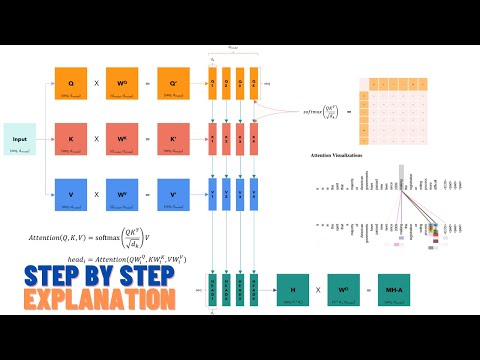
Word Embeddings & Positional Encoding in NLP Transformer model explained - Part 1Подробнее

Let's build GPT: from scratch, in code, spelled out.Подробнее

ChatGPT Position and Positional embeddings: Transformers & NLP 3Подробнее

What is Positional Encoding used in Transformers in NLPПодробнее

Attention Is All You Need - Paper ExplainedПодробнее

Transformer-XL: Attentive Language Models Beyond a Fixed Length ContextПодробнее
Transformers - Part 3 - EncoderПодробнее

Attention is all you need maths explained with exampleПодробнее
Building a ML Transformer in a SpreadsheetПодробнее

Transformer Embeddings - EXPLAINED!Подробнее
Self-Attention and TransformersПодробнее

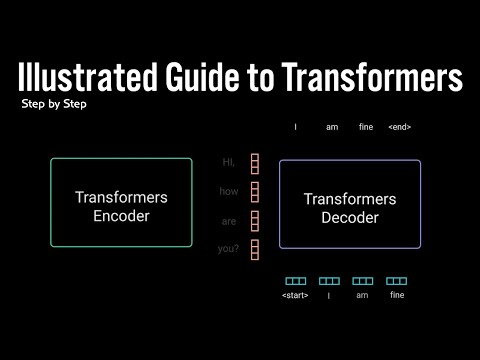
Illustrated Guide to Transformers Neural Network: A step by step explanationПодробнее