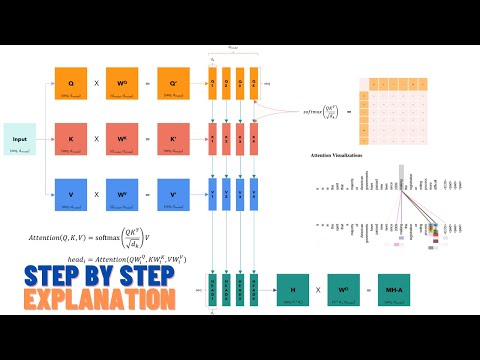
Transformers From Scratch - Part 1 | Positional Encoding, Attention, Layer Normalization
Coding a Multimodal (Vision) Language Model from scratch in PyTorch with full explanationПодробнее
Unit 4 | MCQs | Large Language Models | INT426 | LPUПодробнее

[ 100k Special ] Transformers: Zero to HeroПодробнее
![[ 100k Special ] Transformers: Zero to Hero](https://img.youtube.com/vi/rPFkX5fJdRY/0.jpg)
Coding LLaMA 2 from scratch in PyTorch - KV Cache, Grouped Query Attention, Rotary PE, RMSNormПодробнее

Complete Course NLP Advanced - Part 1 | Transformers, LLMs, GenAI ProjectsПодробнее

LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLUПодробнее

Let's build GPT: from scratch, in code, spelled out.Подробнее

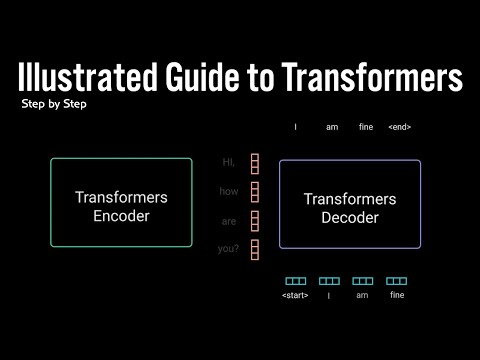
Illustrated Guide to Transformers Neural Network: A step by step explanationПодробнее
Coding a Transformer from scratch on PyTorch, with full explanation, training and inference.Подробнее

Attention is all you need (Transformer) - Model explanation (including math), Inference and TrainingПодробнее