ASPLOS'24 - Lightning Talks - Session 9C - NDPipe: Exploiting Near data Processing for Scalable Infe
ASPLOS'24 - Lightning Talks - Session 9C - NDPipe: Exploiting Near data Processing for Scalable InfeПодробнее

ASPLOS'24 - Lightning Talks - Session 10B - DataFlower: Exploiting the Data flow Paradigm for ServerПодробнее

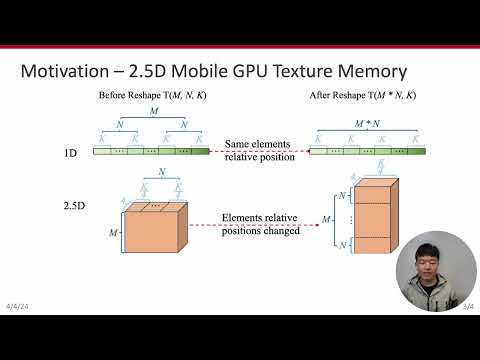
ASPLOS'24 - Lightning Talks - Session 9C - SmartMem: Layout Transformation Elimination and AdaptatioПодробнее
ASPLOS'24 - Lightning Talks - Session 10B - FaaSGraph: Enabling Scalable, Efficient, and Cost EffectПодробнее

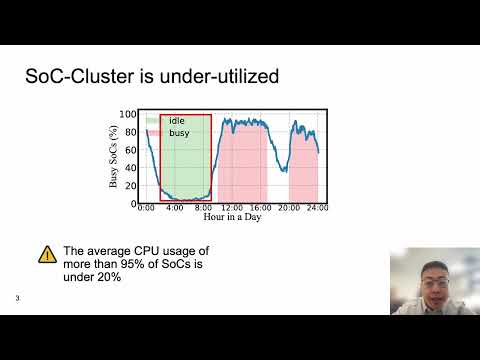
ASPLOS'24 - Lightning Talks - Session 3C - SoCFlow: Efficient and Scalable DNN Training on SoC ClustПодробнее
ASPLOS'24 - Lightning Talks - Session 9C - Dr DNA: Combating Silent Data Corruptions in Deep LearniПодробнее

ASPLOS'24 - Lightning Talks - Session 9A - ngAP: Non blocking Large scale Automata Processing on GPUПодробнее

ASPLOS'24 - Lightning Talks - Session 9C - RECom: A Compiler Approach to Accelerate Recommendation MПодробнее

ASPLOS'24 - Lightning Talks - Session 3B - GIANTSAN: Efficient Memory Sanitization with Segment FoldПодробнее

ASPLOS'24 - Lightning Talks - Session 8B - GMLake: Efficient and Transparent GPU Memory DefragmentatПодробнее

ASPLOS'24 - Lightning Talks - Session 9A - Marple: Scalable Spike Sorting for Untethered Brain MachiПодробнее

ASPLOS'24 - Lightning Talks - Session 5A - C4CAM: A Compiler for CAM based In memory AcceleratorsПодробнее

ASPLOS'24 - Lightning Talks - Session 11B - Efficient Microsecond scale Blind Scheduling with Tiny QПодробнее

ASPLOS'24 - Lightning Talks - Session 3B - FreePart: Hardening Data Processing Software via FrameworПодробнее

ASPLOS'24 - Lightning Talks - Session 5D - MECH: Multi Entry Communication Highway for SuperconductiПодробнее

ASPLOS'24 - Lightning Talks - Session 9D - Exploiting the Regular Structure of Modern Quantum ArchitПодробнее

ASPLOS'24 - Lightning Talks - Session 11C - AdaPipe: Optimizing Pipeline Parallelism with Adaptive RПодробнее

ASPLOS'24 - Lightning Talks - Session 9D - MorphQPV: Exploiting Isomorphism in Quantum Programs to FПодробнее

ASPLOS'24 - Lightning Talks - Session 7C - CrossPrefetch: Accelerating I O Prefetching for Modern StПодробнее
