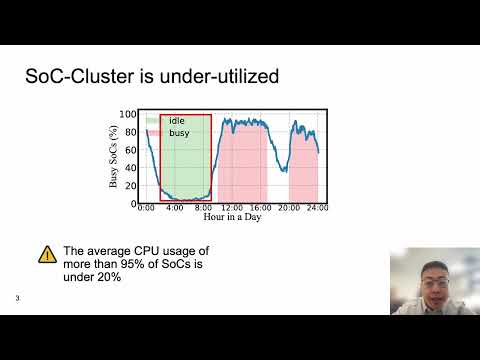
ASPLOS'24 - Lightning Talks - Session 3C - SoCFlow: Efficient and Scalable DNN Training on SoC Clust
ASPLOS'24 - Lightning Talks - Session 3C - SoCFlow: Efficient and Scalable DNN Training on SoC ClustПодробнее
ASPLOS'24 - Lightning Talks - Session 10B - FaaSGraph: Enabling Scalable, Efficient, and Cost EffectПодробнее

ASPLOS'24 - Lightning Talks - Session 10D - A Midsummer Night’s Tree: Efficient and High PerformanceПодробнее

ASPLOS'24 - Lightning Talks - Session 3B - Lightweight Fault Isolation: Practical, Efficient, and SeПодробнее

ASPLOS'24 - Lightning Talks - Session 5A - BaCO: A Fast and Portable Bayesian Compiler OptimizationПодробнее

ASPLOS'24 - Lightning Talks - Session 3C - RAP: Resource aware Automated GPU Sharing for Multi GPU RПодробнее

ASPLOS'24 - Lightning Talks - Session 3C - Training Job Placement in Clusters with Statistical In NeПодробнее

ASPLOS'24 - Lightning Talks - Session 10D - sIOPMP: Scalable and Efficient IO Protection for TEEsПодробнее

ASPLOS'24 - Lightning Talks - Session 8B - GMLake: Efficient and Transparent GPU Memory DefragmentatПодробнее

ASPLOS'24 - Lightning Talks - Session 3B - Enforcing C C++ Type and Scope at Runtime for Control FloПодробнее

ASPLOS'24 - Lightning Talks - Session 9C - SmartMem: Layout Transformation Elimination and AdaptatioПодробнее
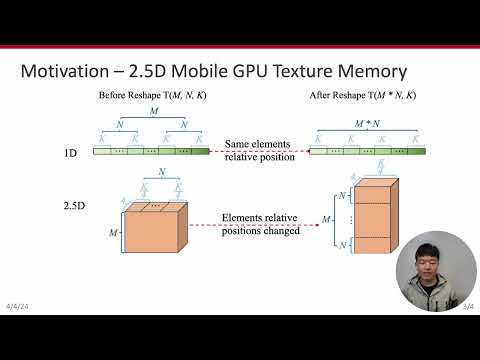
ASPLOS'24 - Lightning Talks - Session 3C - DREAM: A Dynamic Scheduler for Dynamic Real time Multi moПодробнее

ASPLOS'24 - Lightning Talks - Session 6C - Optimal Kernel Orchestration for Tensor Programs with KorПодробнее

ASPLOS'24 - Lightning Talks - Session 11B - Efficient Microsecond scale Blind Scheduling with Tiny QПодробнее

ASPLOS'24 - Lightning Talks - Session 1C - A Journey of a 1,000 Kernels Begins with a Single Step: AПодробнее

ASPLOS'24 - Lightning Talks - Session 3A - Loupe: Driving the Development of OS Compatibility LayersПодробнее

ASPLOS'24 - Lightning Talks - Session 4B - λFS: A Scalable and Elastic Distributed File System MetadПодробнее

ASPLOS'24 - Lightning Talks - Session 9A - Marple: Scalable Spike Sorting for Untethered Brain MachiПодробнее

ASPLOS'24 - Lightning Talks - Session 11C - AdaPipe: Optimizing Pipeline Parallelism with Adaptive RПодробнее
