ASPLOS'24 - Lightning Talks - Session 9B - Achieving Near Zero Read Retry for 3D NAND Flash Memory
ASPLOS'24 - Lightning Talks - Session 9B - Achieving Near Zero Read Retry for 3D NAND Flash MemoryПодробнее

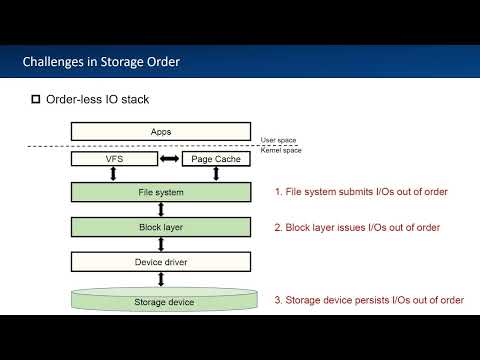
ASPLOS'24 - Lightning Talks - Session 9B - LazyBarrier: Reconstructing Android IO Stack for Barrier-Подробнее
ASPLOS'24 - Lightning Talks - Session 3D - MAGIS: Memory Optimization via Coordinated Graph TransforПодробнее

ASPLOS'24 - Lightning Talks - Session 11A - ZENO: A Type based Optimization Framework for Zero KnowlПодробнее

ASPLOS'24 - Lightning Talks - Session 3B - FreePart: Hardening Data Processing Software via FrameworПодробнее

ASPLOS'24 - Lightning Talks - Session 9B - AERO: Adaptive Erase Operation for Improving Lifetime andПодробнее

ASPLOS'24 - Lightning Talks - Session 9B - Eliminating Storage Management Overhead of DeduplicationПодробнее

ASPLOS'24 - Lightning Talks - Session 9B - BypassD: Enabling fast userspace access to shared SSDsПодробнее

ASPLOS'24 - Lightning Talks - Session 3B - GIANTSAN: Efficient Memory Sanitization with Segment FoldПодробнее

ASPLOS'24 - Lightning Talks - Session 9A - JUNO: Optimizing High Dimensional Approximate Nearest NeiПодробнее

ASPLOS'24 - Lightning Talks - Session 10B - FaaSGraph: Enabling Scalable, Efficient, and Cost EffectПодробнее

ASPLOS'24 - Lightning Talks - Session 9D - Exploiting the Regular Structure of Modern Quantum ArchitПодробнее

ASPLOS'24 - Lightning Talks - Session 11B - Efficient Microsecond scale Blind Scheduling with Tiny QПодробнее

ASPLOS'24 - Lightning Talks - Session 2C - TrackFM: Far out Compiler Support for a Far Memory WorldПодробнее

ASPLOS'24 - Lightning Talks - Session 2B -Last Level Cache Side Channel Attacks Are Feasible in theПодробнее

ASPLOS'24 - Lightning Talks - Session 9A - Marple: Scalable Spike Sorting for Untethered Brain MachiПодробнее

ASPLOS'24 - Lightning Talks - Session 7B - SIRO: Empowering Version Compatibility in Intermediate ReПодробнее
ASPLOS'24 - Lightning Talks - Session 9C - NDPipe: Exploiting Near data Processing for Scalable InfeПодробнее

ASPLOS'24 - Lightning Talks - Session 8B - GMLake: Efficient and Transparent GPU Memory DefragmentatПодробнее
