Panoptic Lifting for 3D Scene Understanding with Neural Fields (CVPR'2023)
Panoptic Lifting (CVPR 2023) with Yawar Siddiqui on Talking papersПодробнее

[CVPR2023] Instant-NVR: Instant Neural Volumetric Rendering for Human-object InteractionsПодробнее
![[CVPR2023] Instant-NVR: Instant Neural Volumetric Rendering for Human-object Interactions](https://img.youtube.com/vi/8F-D7kaZmJk/0.jpg)
(CVPR 2023) PLA: Language-Driven Open-Vocabulary 3D Scene UnderstandingПодробнее

POSA: Populating 3D Scenes by Learning Human-Scene Interaction (CVPR 2021)Подробнее

[CVPR'23] OpenScene: 3D Scene Understanding with Open VocabulariesПодробнее
![[CVPR'23] OpenScene: 3D Scene Understanding with Open Vocabularies](https://img.youtube.com/vi/jZxCLHyDJf8/0.jpg)
Learning 3D Scene Priors with 2D Supervision (CVPR'2023)Подробнее

CVPR 2023 Paper Compilation - TUM Visual Computing Lab & CollaboratorsПодробнее

Panoptic Lifting for 3D Scene Understanding with Neural Fields (CVPR'2023)Подробнее

RetrievalFuse: Neural 3D Scene Reconstruction with a Database (ICCV'2021)Подробнее

Deep Learning for 3D Scene Understanding by Eskil JörgensenПодробнее

NeRFusion: Fusing Radiance Fields for Large Scale Scene Reconstruction | CVPR 2022Подробнее

[CVPR2023] ReRF: Neural Residual Radiance Fields for Streamably Free-Viewpoint VideosПодробнее
![[CVPR2023] ReRF: Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos](https://img.youtube.com/vi/dFvwaI1h-nc/0.jpg)
[CVPR 2023] Self-supervised Pre-training with Masked Shape Prediction for 3D Scene UnderstandingПодробнее
![[CVPR 2023] Self-supervised Pre-training with Masked Shape Prediction for 3D Scene Understanding](https://img.youtube.com/vi/DLDZpA_LIGU/0.jpg)
[CVPR2023] Relightable Neural Human Assets from Multi-view Gradient IlluminationsПодробнее
![[CVPR2023] Relightable Neural Human Assets from Multi-view Gradient Illuminations](https://img.youtube.com/vi/EFcgBDbxJHA/0.jpg)
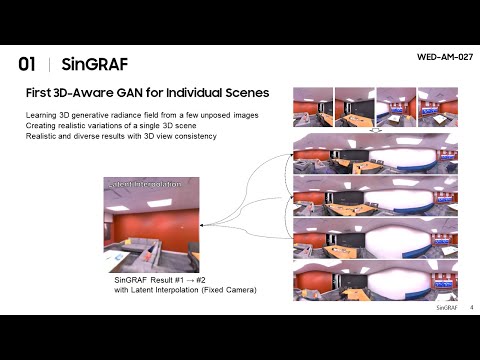
SinGRAF: Learning a 3D Generative Radiance Field for a Single Scene | CVPR 2023Подробнее
[CVPR 2023] Behind the Scenes: Density Fields for Single View ReconstructionПодробнее
![[CVPR 2023] Behind the Scenes: Density Fields for Single View Reconstruction](https://img.youtube.com/vi/0VGKPmomrR8/0.jpg)