LLM Jargons Explained: Part 2 - Multi Query & Group Query Attent
LLM Jargons Explained: Part 2 - Multi Query & Group Query AttentПодробнее

Multi-Head Attention vs Group Query Attention in AI ModelsПодробнее

LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLUПодробнее

DeciLM 15x faster than Llama2 LLM Variable Grouped Query Attention Discussion and DemoПодробнее

Deep dive - Better Attention layers for Transformer modelsПодробнее

LLM Jargons ExplainedПодробнее

Variants of Multi-head attention: Multi-query (MQA) and Grouped-query attention (GQA)Подробнее
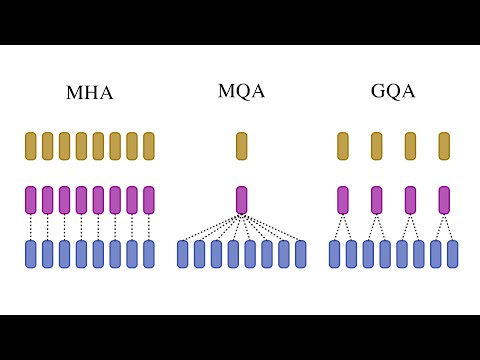
Multi Query & Group Query AttentionПодробнее

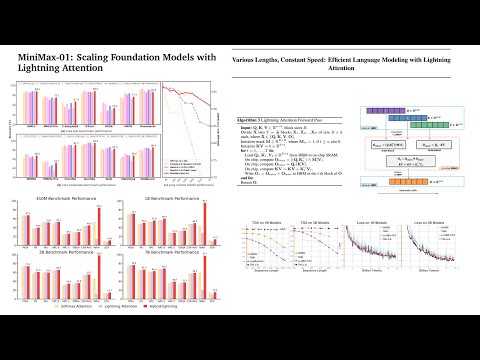
MiniMax-01: Scaling Foundation Models with Lightning AttentionПодробнее
Deciding Which LLM to UseПодробнее

What is Llama Index? how does it help in building LLM applications? #languagemodels #chatgptПодробнее
Coding LLaMA 2 from scratch in PyTorch - KV Cache, Grouped Query Attention, Rotary PE, RMSNormПодробнее

LLMs | Advanced Attention Mechanisms-I | Lec 8.1Подробнее

LLaMA 2 Explained: Pretraining, Iterative FineTuning, Grouped Query Attention, Ghost AttentionПодробнее

How Large Language Models WorkПодробнее
