Scaling your Data Pipelines with Apache Spark on Kubernetes

What is Data Pipeline? | Why Is It So Popular?Подробнее
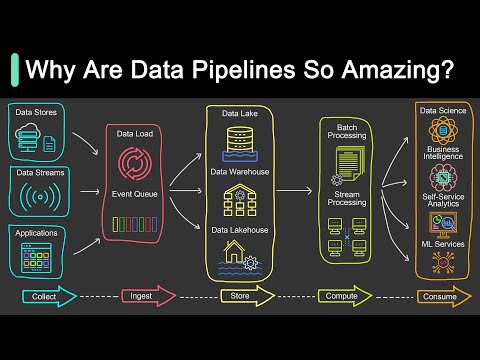
Datadog on Data Engineering Pipelines: Apache Spark at ScaleПодробнее

Ocean for Apache Spark Deep DiveПодробнее

Apache Spark on Kubernetes—Lessons Learned from Launching Millions of Spark ExecutorsПодробнее

RayDP: Build Large-scale End-to-end Data Analytics and AI Pipelines Using Spark and RayПодробнее

Building Scalable Data Pipelines With Argo Workflows | David Joyce | Conf42 Kube Native 2022Подробнее

Democratizing data at Zillow with dbt, Airflow, Spark, and KubernetesПодробнее

Beyond Experimental: Spark on Kubernetes - Weiwei Yang, AppleПодробнее

Ready to run! Get Started with Spark on KubernetesПодробнее

Distributed data pipeline using Airflow and Spark on kubernetesПодробнее
Deploying Spark on Kubernetes using DockersПодробнее
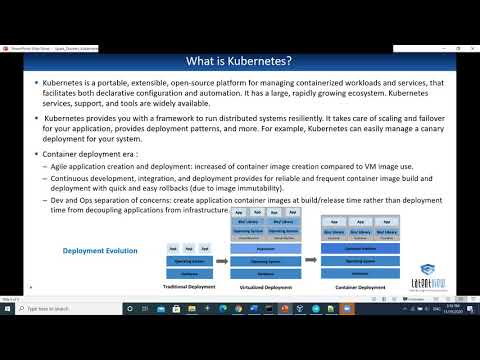
Getting Started with Apache Spark on KubernetesПодробнее

Spark on Kubernetes: Why and How to Migrate Your Spark Pipelines to Cloud-Native Apache SparkПодробнее

AWS re:Invent 2020: Scaling MLOps on Kubernetes with Amazon SageMaker OperatorsПодробнее

Infrastructure Agnostic Machine Learning Workload DeploymentПодробнее

Declarative Pipelines & Intelligent Orchestration - Data’s Missing Link - Sean Knapp, Ascend.ioПодробнее

Scale By The Bay 2020: Jean-Ives Stephan, Cloud-Native Apache Spark: why & how to migrate your SparkПодробнее

Build Efficient, High-performance Data Pipelines with IICSПодробнее

Build Large-Scale Data Analytics and AI Pipeline Using RayDPПодробнее
