No more Fine-Tuning: Unsupervised ICL+

Bulk Skimming AI Paper Abstracts - Oct 13, 2024Подробнее

Fine-tuning vs. Instruction-tunning explained in under 2 minutesПодробнее

Stanford XCS224U: NLU I In-context Learning, Part 3: Current Moment I Spring 2023Подробнее

Pretraining vs Fine-tuning vs In-context Learning of LLM (GPT-x) EXPLAINED | Ultimate Guide ($)Подробнее

RAG vs. Fine TuningПодробнее

ICCV 2023 - MAXI: Unsupervised Finetuning for Zero-Shot Action Recognition with Language KnowledgeПодробнее

Fine Tune a model with MLX for OllamaПодробнее

Fine Tune LLaMA 2 In FIVE MINUTES! - "Perform 10x Better For My Use Case"Подробнее

How To Fine-Tune Llama 3.1 in 11 MinutesПодробнее

LLM Fine Tuning - Explained!Подробнее

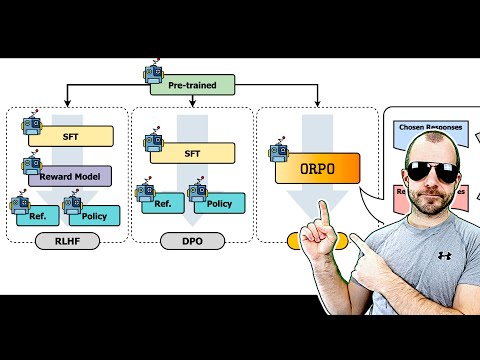
ORPO: Monolithic Preference Optimization without Reference Model (Paper Explained)Подробнее
Low-rank Adaption of Large Language Models Part 2: Simple Fine-tuning with LoRAПодробнее

Instruction Fine-Tuning and In-Context Learning of LLM (w/ Symbols)Подробнее

Fine-tuning a Neural Network explainedПодробнее

Fine Tuning OpenAI Models Walkthrough - How and WhyПодробнее

Fine-tune ChatGPT w/ in-context learning ICL - Chain of Thought, AMA, reasoning & acting: ReActПодробнее

Do You Even Need Fine-Tuning?Подробнее
