Designing the Next Generation of Data Pipelines at Zillow with Apache Spark

Empowering Zillow’s Developers with Self-Service ETLПодробнее
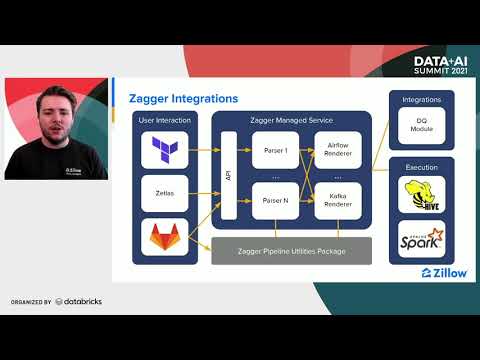
Apache Spark as a Platform for Powerful Custom Analytics Data Pipeline: Talk by Mikhail ChernetsovПодробнее

Sam Elamin - Data pipelines with Apache SparkПодробнее

Processing 2000 TBs per day of network data at Netflix with Spark and AirflowПодробнее

Building a Distributed Collaborative Data Pipeline with Apache SparkПодробнее

The five levels of Apache Spark - Data EngineeringПодробнее

Designing and Building Next Generation Data Pipelines at Scale with Structured Streaming-Burak YavuzПодробнее
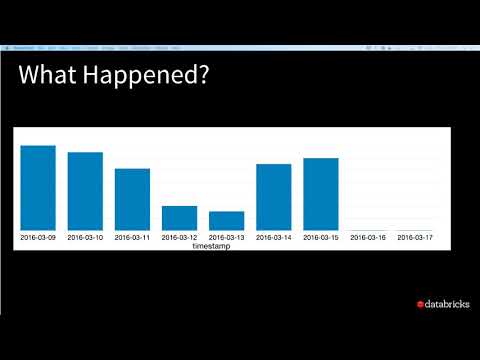
Data Pipeline OverviewПодробнее

Building Data Pipelines with Spark and StreamSets (Pat Patterson)Подробнее

Lessons Learned Developing and Managing Massive 300TB+ Apache Spark PipelinesПодробнее

Apache Spark in 60 SecondsПодробнее

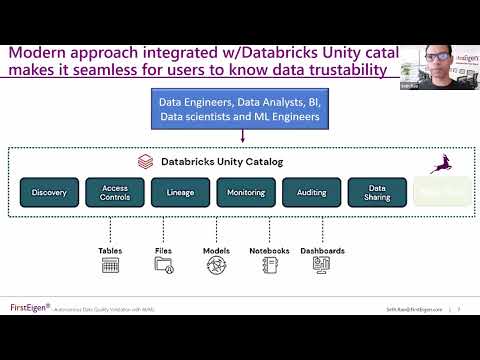
Resilient Data Pipelines in Databricks w/Data Trust Scores in Unity CatalogПодробнее
Build Production Data Pipelines at Scale with Accelerated Spark On PremisesSumit Gupta IBMПодробнее

What the HECK is a “Data Pipeline”? 👩🏻🔧📊🪠Подробнее

Democratizing data at Zillow with dbt, Airflow, Spark, and KubernetesПодробнее

🤔What is data pipeline ? #shorts #ytshorts #datapipelineПодробнее

Creating a New DataFrame in Apache Spark from an Existing DataFrame: Step-by-Step GuideПодробнее

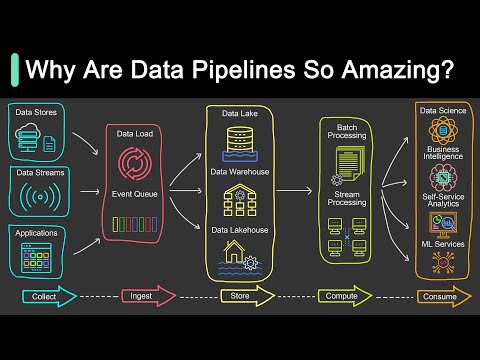
What is Data Pipeline? | Why Is It So Popular?Подробнее
Is Data Engineering the New Best Job?Подробнее
