Coding Multihead Attention for Transformer Neural Networks
Lecture 79# Multi-Head Attention (Encoder-Decoder Attention) in Transformers | Deep LearningПодробнее
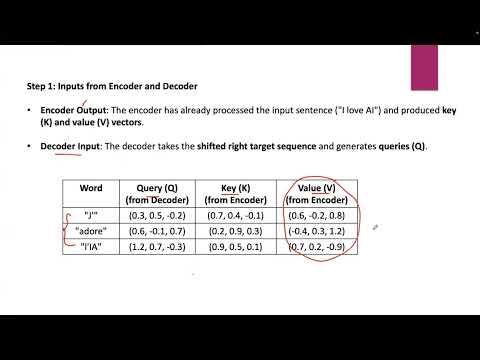
Transformer Architecture and Components | AIML End-to-End Session 205Подробнее

DeepSeek Multi-Head Attention Explained - Part 1Подробнее
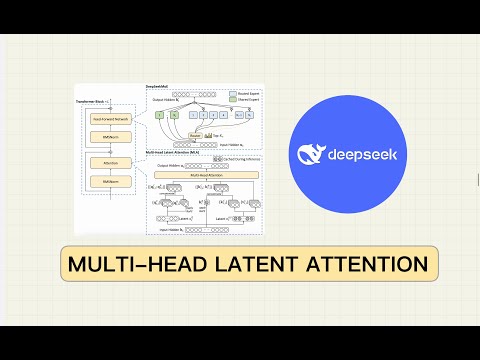
Attention Mechanism Explained: The Secret Behind Transformers, BERT & GPT! 🚀 | LLM | #aiexplainedПодробнее
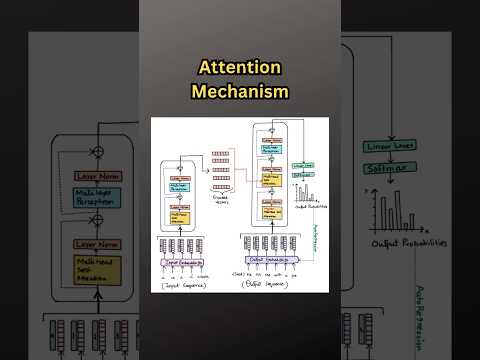
AI Devlog: Transformer – Understanding Multi-Head AttentionПодробнее

Multi-Head Attention Handwritten from ScratchПодробнее

Bài 5: Cách lập trình Single-head Attention và Multi-head Attention sử dụng Pytorch từ số không.Подробнее
Lecture 75# Multi Head Attention in TransformersПодробнее
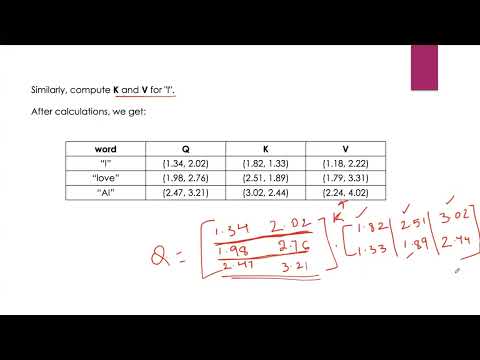
Transformer Architecture Part 2 Explaining Self Attention and Multi Head AttentionПодробнее

Attention is All You Need: Ditching Recurrence for Good!Подробнее

coding a chatgpt like transformer from scratch in pytorchПодробнее

attention is all you need paper explainedПодробнее

Week 6 - Lab 3 (Multi-Head Attention)Подробнее
Transformer Neural Networks Explained | Before AGI PodcastПодробнее

Lec 15 | Introduction to Transformer: Self & Multi-Head AttentionПодробнее

Coding Transformer From Scratch With Pytorch in Hindi Urdu || Training | Inference || ExplanationПодробнее

⚡ Building a Transformer Model from Scratch: Complete Step-by-Step GuideПодробнее
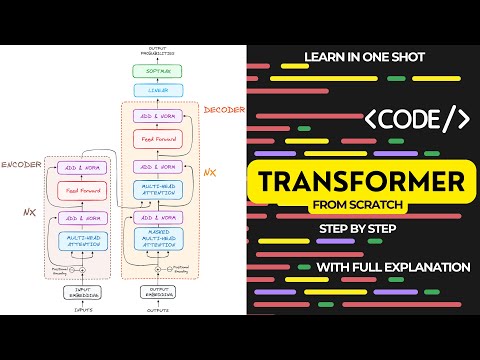
Transformers Explained | Simple Explanation of TransformersПодробнее

Transformers - Part - 2 Transformer Encoder with coding (PS)Подробнее

DeepSeek V3 Code Explained Step by StepПодробнее
