Best Practices: How To Build Scalable Data Pipelines for Machine Learning
Scalable Data Pipelines for ML: Integrating Argo Workflows and dbt | Hauke BrammerПодробнее

Best Practices for Building Data Pipelines! How to Build the Best Data PipelinesПодробнее

Data Pipeline Design and Best PracticesПодробнее

I built data pipelines at Netflix that ran 2000 TBs per day, here’s what I learned about huge data!Подробнее

Building Production-Ready RAG Applications: Jerry LiuПодробнее

Best Practices for Scala Spark Developers in 2024 | iCert GlobalПодробнее

Apidays Singapore 2024 - Designing a scalable ML Ops Pipeline: Insights and best practices.Подробнее

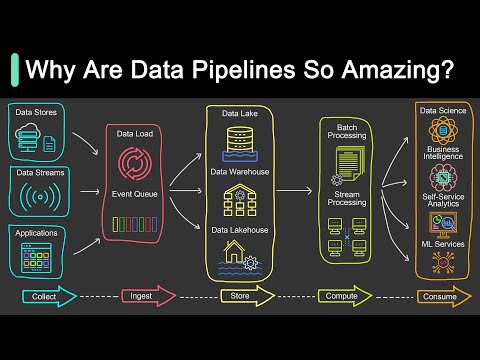
What is Data Pipeline? | Why Is It So Popular?Подробнее
Scalable Annotation Pipelines | SuperAnnotate Webinars (November 18, 2023)Подробнее

Best Practices to build Scalable AI Solutions on AWSПодробнее

How to set up an ML data labeling pipeline: best practices and examplesПодробнее

On-Shelf Availability Prediction: IntroПодробнее

Back to Basics: Building an Event Driven Serverless ETL Pipeline on AWSПодробнее

673: Taipy, the open-source Python application builder — with Vincent GosselinПодробнее

Nebula: The Journey of Scaling Instacart’s Data Pipelines with Apache Spark™ and LakehouseПодробнее

DBT Models - How to Build Scalable Data Pipelines with data build toolПодробнее

Scaling with Databricks to Run Thousands of Data Pipelines: Design and Architecture Best PracticesПодробнее

Back to Basics: Build and Deploy Scalable Machine Learning Systems on Open-Source PlatformsПодробнее

What is Medallion Architecture? Scalable Data Lakes | 2023Подробнее

Building scalable and reliable data pipelines using Debezium and Kafka | PlatformCon 2023Подробнее
